Power Automate Desktop: Edge を使ってPDFのページ数を取得
Power Automate for Desktop から Edgeを使って、PDFファイルのページ数を取得してみます。Edgeは Chromium 版です。
フローの全体です。特定のフォルダーにあるPDFファイルをすべて処理しています。

1. 「フォルダー内のファイルを取得」アクションで PDF ファイルを取得します。

フォルダー: この例では c:\NK Temp
ファイルフィルター: *.pdf
2. 「新しいリストの作成」アクションでリストを作成します。

動作確認用のものなので、PDFファイルをその都度処理して終わりなら不要です。
3. 「For each」アクションで、1. で取得したPDFファイルを一つずつ処理します。

4. 「アプリケーションの実行」アクションで Edge を起動します。

アプリケーションパス: msedge.exe
コマンドライン引数: "--new-window" %CurrentItem.FullName%
アプリケーション起動後: アプリケーションの読み込みを待機
アプリケーションパスは絶対パスで指定するように書いてありますが、とりあえず msedge.exe のみで動いています。パスが通っているのでしょう。うまくいかなければフルパスを指定しましょう。私の環境では次の通りでした。
"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
コマンドライン引数には --new-window を指定して、新しいウィンドウで開くようにしています。最初ダブルクォーテーションを付けなかったらうまくいかず、パスにもつけたらやはりうまくいかず、上の指定でようやく新しいウィンドウで開くようになりました。
「アプリケーションの読み込みを待機」は機能しているような気がします。
5. 「ウィンドウの取得」アクションでウィンドウハンドル(AutomationWindow.Handle)を取得します。
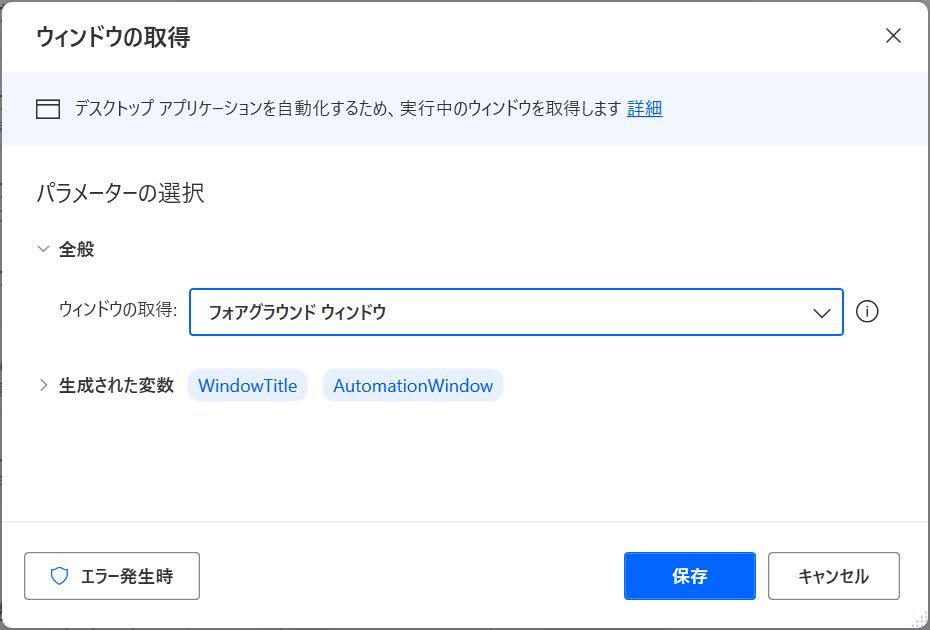
ウィンドウハンドルを使って確実な操作をします。
ここでうまく取れないようだと、何らかの対策が必要です。
6. 「ウィンドウコンテンツを待機」アクションで、ページ番号を待機します。
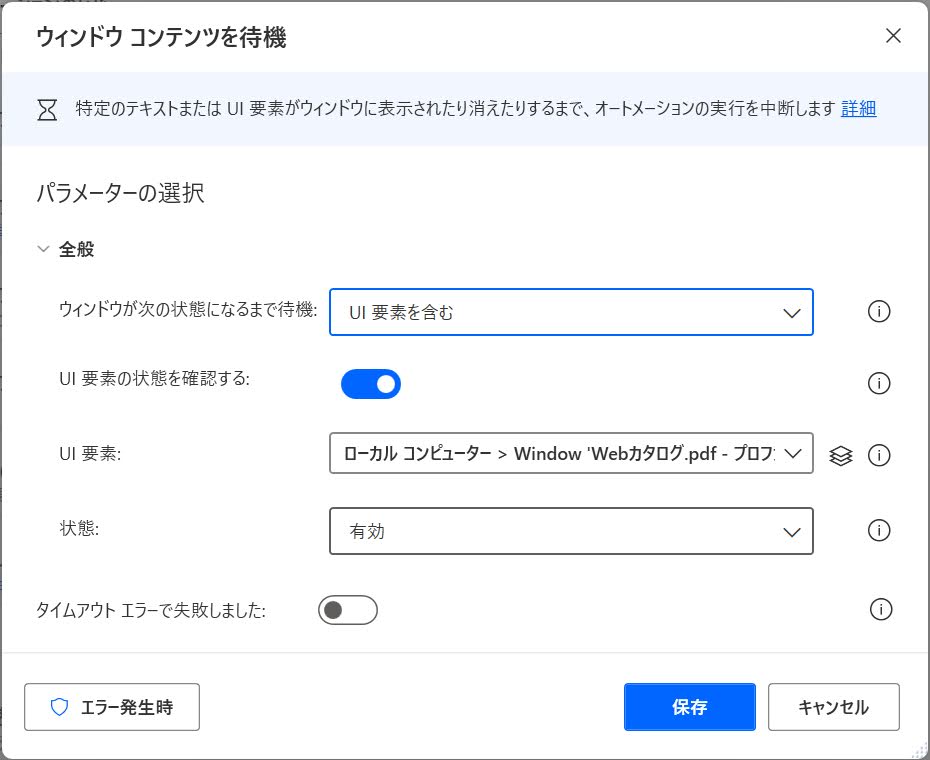
UI要素には「ページ番号」テキストボックスを指定します。

UI要素編集ペインで、取得したEdit UI要素をダブルクリックします。

1番目の要素の Name 属性の値にファイル名が入っているため、他のファイルを処理できなくなるのでチェックを外します。
 |
| 図ではチェックが入っていますが外します |
ページ番号の上のウィンドウをダブルクリックします。

テキストボックス同様に、こちらも Name にファイル名が入っているためチェックを外します。

右上のテキストエディターを有効にして、セレクターに次の文字列を追加します。
[handle="%AutomationWindow.Handle%"]

「ウィンドウの取得」アクションで取得したウィンドウハンドルのウィンドウだけを操作対象とするための制限です。これがないとEdgeのウィンドウが複数開いていた際に、ウィンドウを特定できなくなります。
7. 「ウィンドウにあるUI要素の詳細を取得する」アクションでページ番号テキストボックスの名前を取得します。

UI要素には取得済みのページ番号を指定します。
属性名には Name を指定します。
これによりページ番号につけられている「Edit '1 から 56 ページまでの任意のページに移動する'」のような名前を取得することができます。
取得した名前は AttributeValue に入ります。
8. 「ウィンドウを閉じる」アクションでウィンドウを閉じます。

最初は キーの送信で Ctrl-W を送ってみましたが、たまに閉じられないウィンドウがあったため、こちらに切り替えました。UI要素を操作すると若干遅いけれど、こちらの方が確実なようです。
9. 「テキストの分割」アクションを使って 7. で取得したAttributeValueを分割します。

7.の処理で取得した名前は「Edit '1 から 56 ページまでの任意のページに移動する'」のような形式で、幸いにも半角スペースで区切られていました。
結果は TextLIst に入ります。
10. 「項目をリストに追加」アクションで、ページ数をリストに追加します。

ページ数はTextListの3番目にあるので、インデックス2を指定して取り出します。(リストのインデックスは 0 から始まっているので2は3番目を意味します)
11. 「End」アクション。For eachの終わりです。

12. List を表示します。

おわりに
このフローを作るのにはなかなか苦戦しました。
海外のサイトには、Endキーを送って最後のページまでスクロールしてページ番号を取得するという方法が提案されていました。しかしこれでは、最後までスクロールしたかどうかをどう判定するの、という問題があります。
総ページ数をUI要素として取得できれば簡単だったのですが、画面はそういう作りにはなっておらず、Inspect.exe を使ってみてもその存在を確認することはできませんでした。
Inspect 上では次のように表示されます。

そのため、次のようなセレクターで取れそうな気もするのですが、結果は要素が見つかりません、でした。
toolbar[Class="c0154 c0160 c0136 c0145"][Name="PDF バー"] > group:eq(1) > label:eq(1)
不思議なことに、ツールバーのテキストをすべて取得してみてもその中に総ページ数は含まれていません。
これ以外にも厄介な点はありましたが、そちらは先にAcrobat版を完成させていたので、何とかなりました。
Power Automate Desktop: Acrobat を使ってPDFのページ数を取得




コメント
コメントを投稿